PDFを書き起こしてテキストで書く方法
無料のオンライン変換サイトを使用する
フリーソフトウェアを使ってテキストを抽出する方法については、以下の記事「PDFからテキスト(テキスト)を抽出する方法」のセクションを参照してください。
これは、WindowsとMacの両方で使用することができます。
PDFから画像やテキストを抽出する方法
グーグルドライブにアクセスする
Googleドライブ(https://drive.google.com/)に移動し、[新規作成]ボタンを押します。
ファイルのアップロード
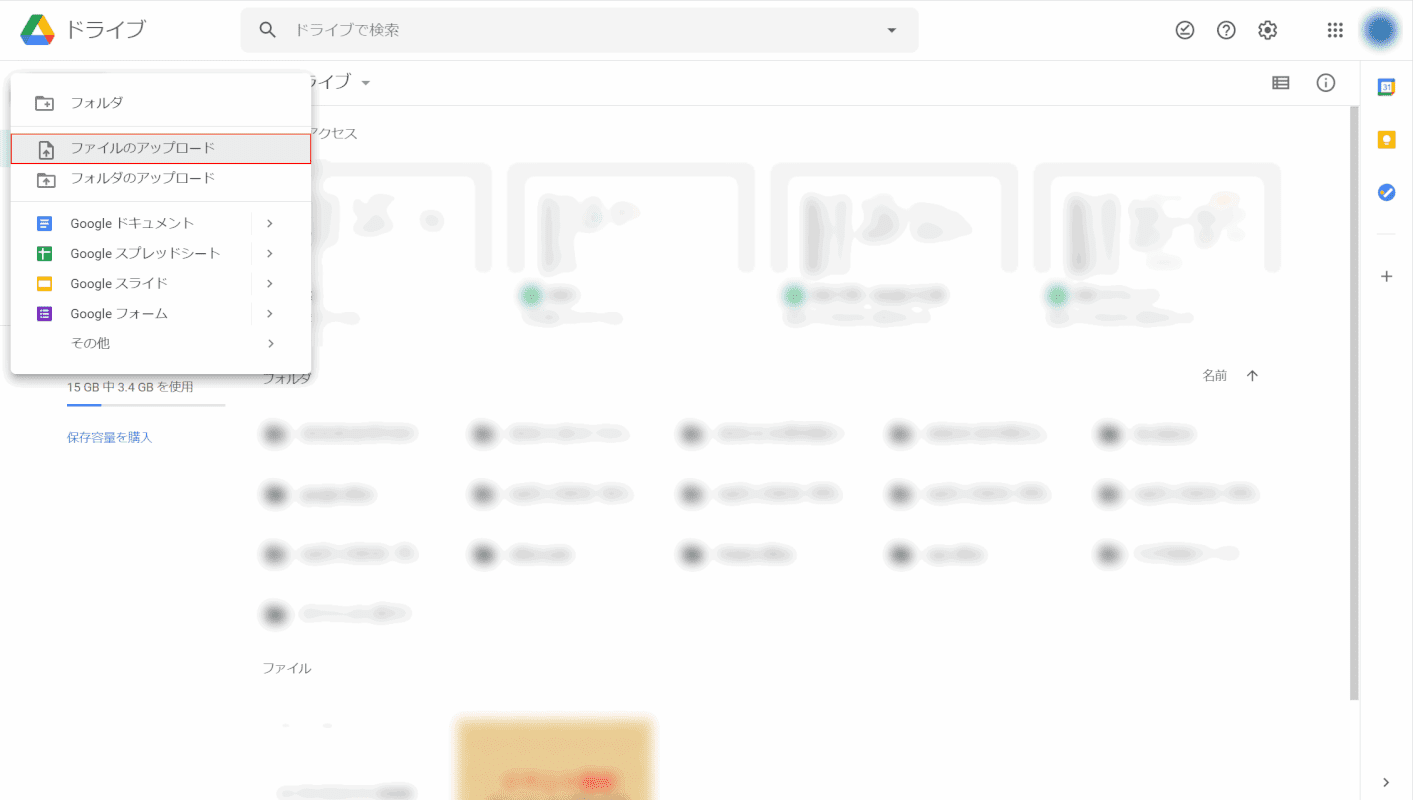
出てきたメニューから、[Upload file].
ファイルの選択
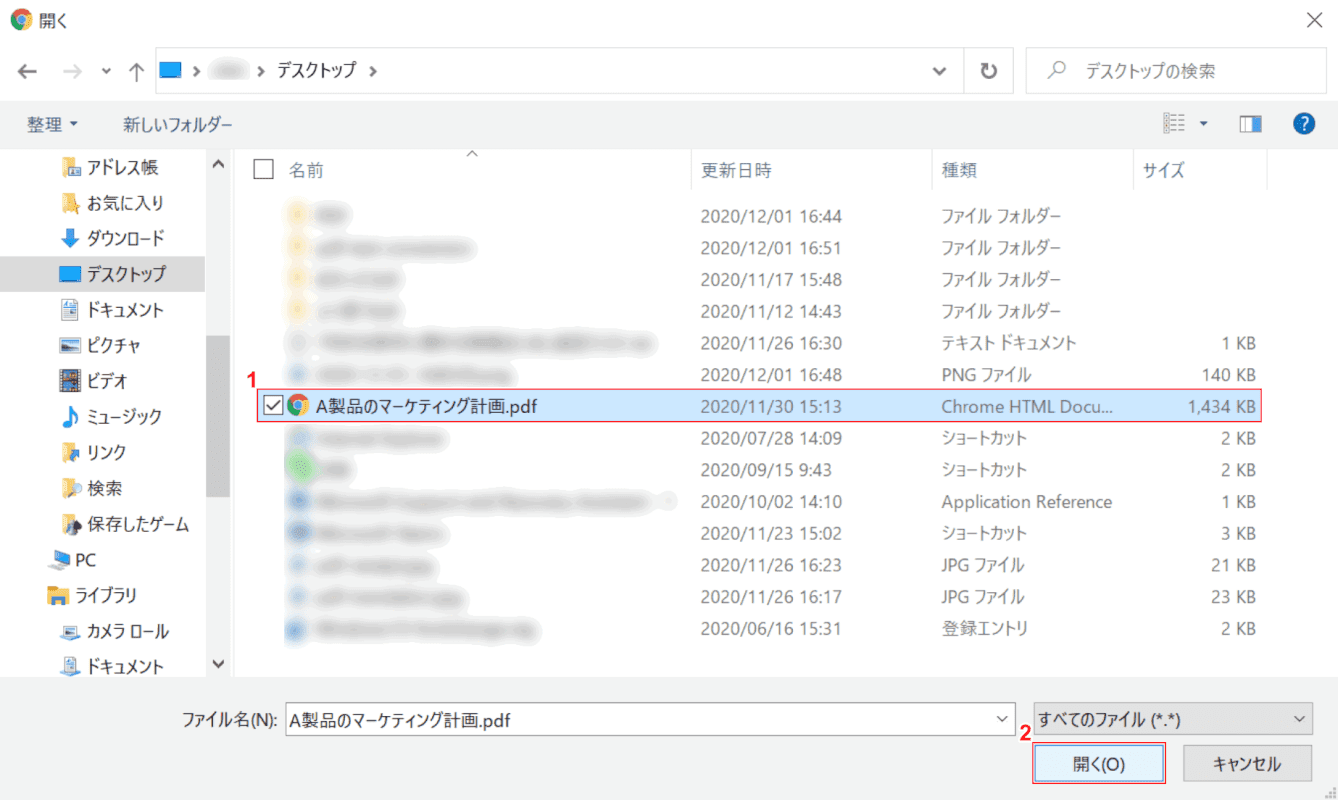
「開く」ダイアログボックスが表示されます。(1) 選択[Arbitrary file]とプレス (2)[Open]ボタン。
グーグルドキュメントで開く
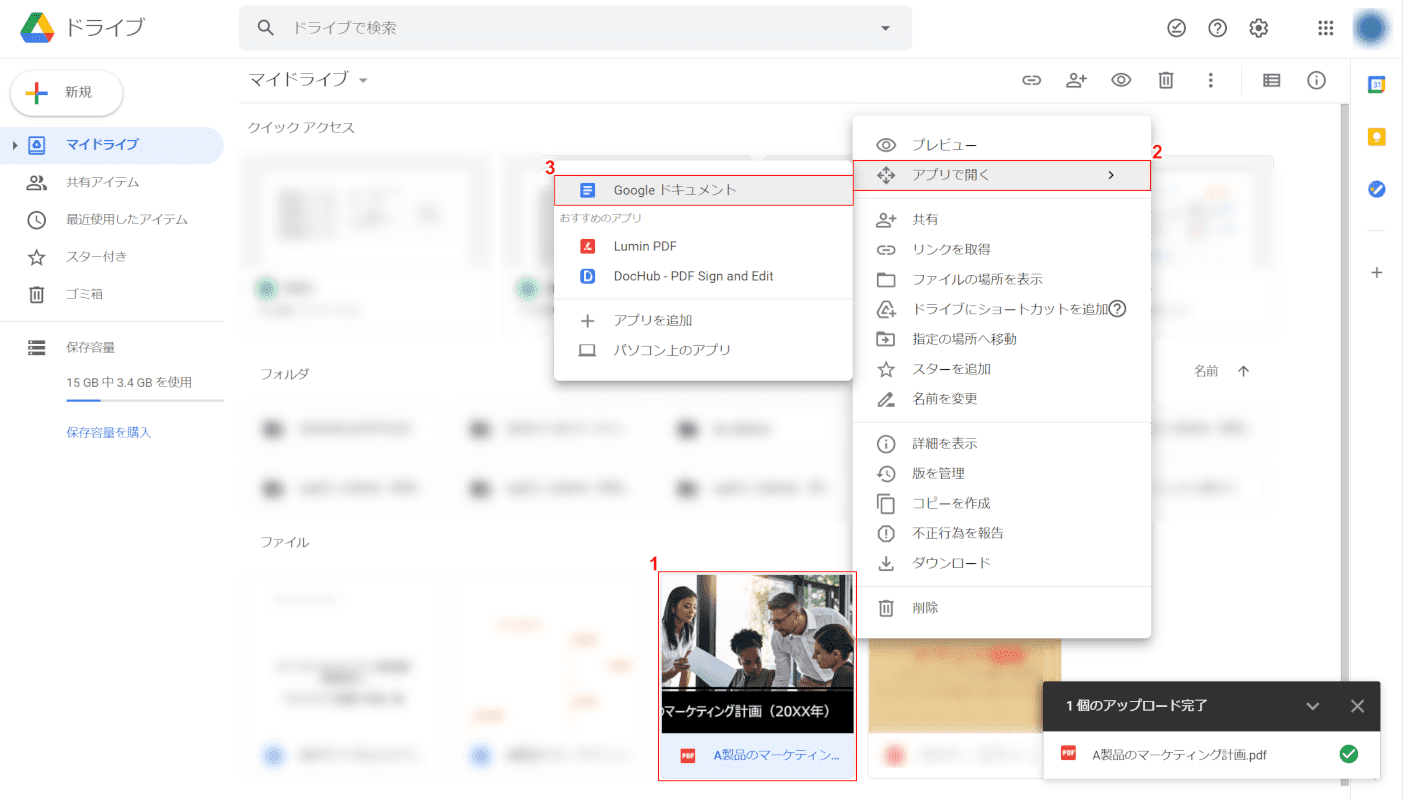
(1) 右クリック[Uploaded file].(2) 選択[Open in app](3)[Google Docs].
テキスト抽出の完了

Google ドキュメントが新しいタブで開きます。これでテキストの抽出が完了しました。
お使いの携帯電話(iPhone)でアプリを使用する
CamScanner というアプリを使ってテキストを抽出する方法について説明します。
CamScannerは、手書きのメモや領収書などの重要な文書を高速でスキャンして保存し、画像やPDFからテキストを簡単に抽出できます。
アプリをインストールする

アプリストアカムスキャナーアプリをインストールします。
無料メンバーシップにサインアップする
CamScannerは、無料会員登録により、1日4回までOCRを使用することができます。
以下、会員登録の方法を説明します。

カムスキャナーアプリを開きます。

選ぶ[Me]画面の右下にあります。
押す[Login/ Register].
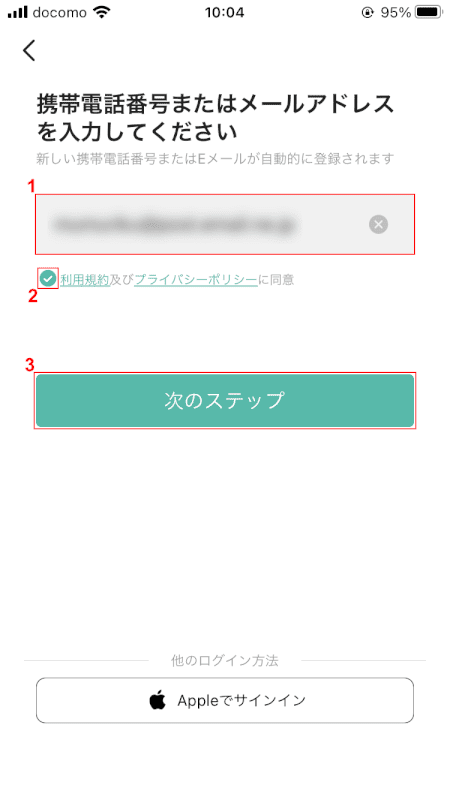
(1)「メールアドレス」を入力し、(2)項目を確認する[Agree to the Terms of Use and Privacy Policy].
(3)[Next Step]ボタン。
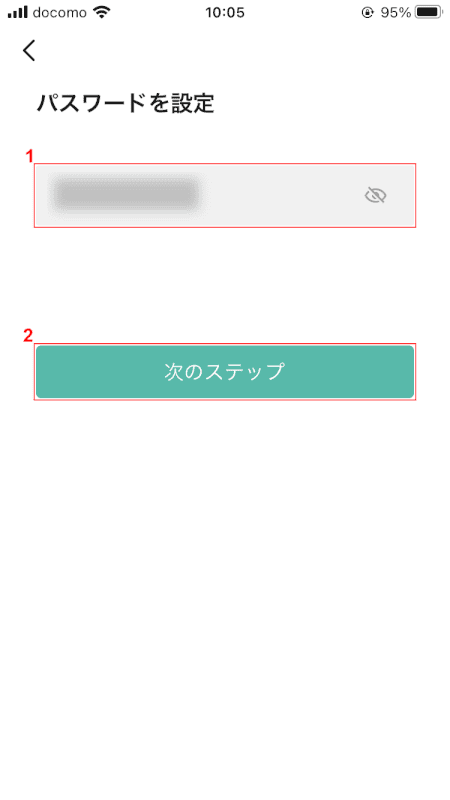
(1)「パスワード」と入力し、(2)を押す[Next Step]ボタン。

入力したメールアドレスに確認メールが届きました。
[[Please confirm your email address]ボタン。
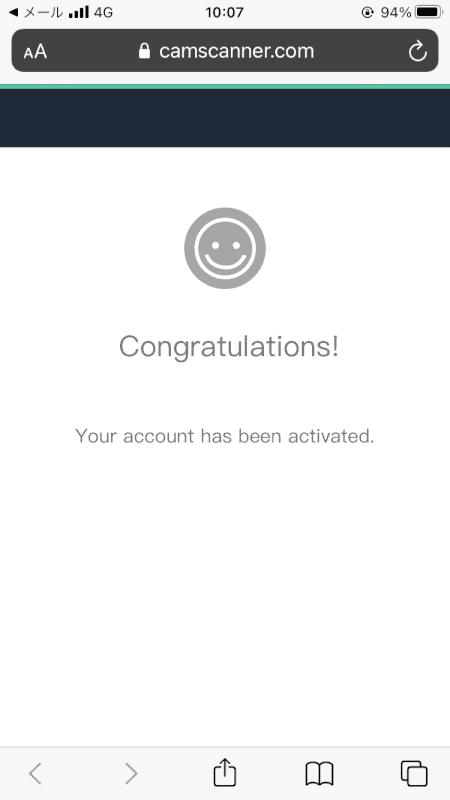
メールアドレスが確認されました。
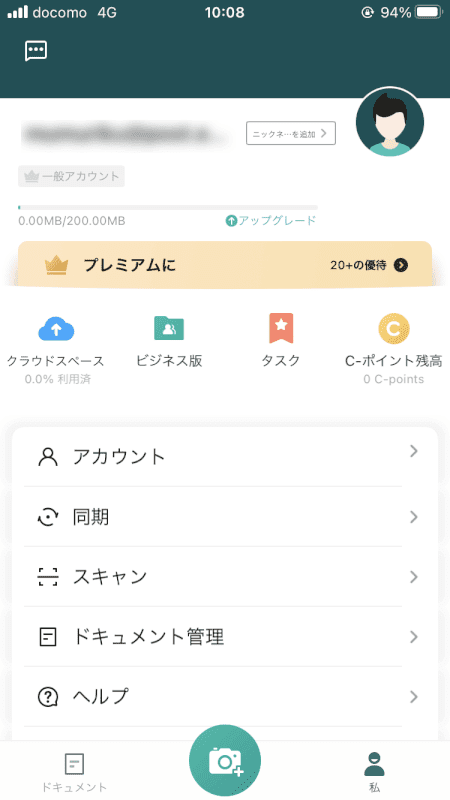
CamScannerアプリに戻ると、メンバーとして登録されています。
PDF からテキストを抽出する
PDF からテキストを抽出する方法については、こちらをご覧ください。

今回は、「ファイル」アプリに保存されたPDFテキストを抽出します。
開く[File]アプリ。
長押し[Any PDF].
出てきたメニューから、[Share].
(1)[Scroll “Sideways" of “App Menu", (2) Select the app of[CamScanner].

[[Save]ボタン。

[[Save]ボタン。
PDF がアップロードされました。

選ぶ[Page where you want to extract text].
※無料会員は抽出できるテキスト数に制限がありますので、制限を超えたデータ数から抽出したい場合は別途料金をお支払いいただく必要があります。

[テキスト]を選択します。
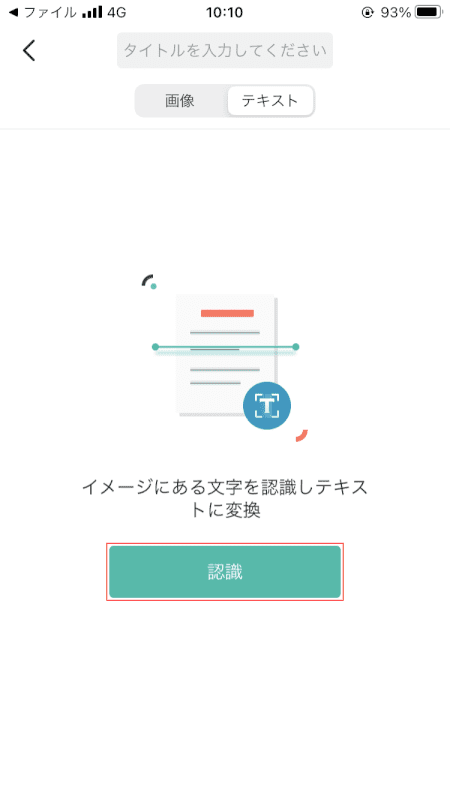
[[Recognize]ボタン。
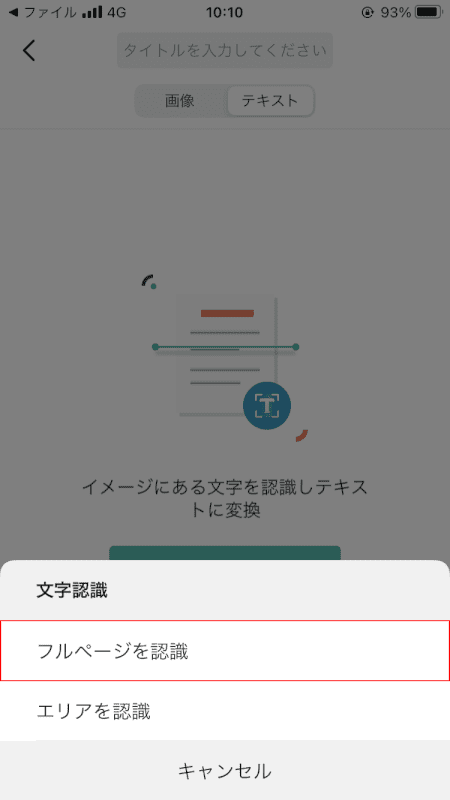
選ぶ[Any character recognition range (e.g. recognize full page)].
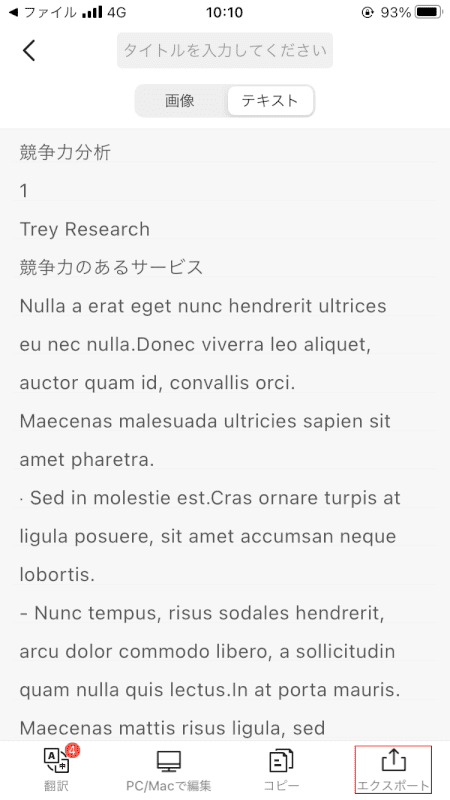
選ぶ[Export]画面の右下にあります。
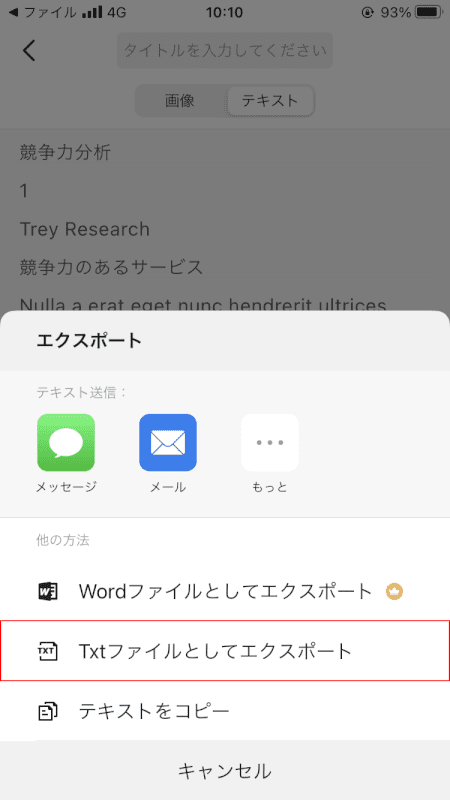
[Txt ファイルとしてエクスポート]を選択します。
任意の共有方法(電子メールなど)を選択します。
(1)「メールアドレスに送信」と入力し、(2)を押す[↑]ボタン。
I rec私が入力した電子メールアドレスでTxtファイルをeived。
ダブルクリック[Attachment]をクリックして開きます。

これでテキストの抽出が完了しました。
画面右上の「共有」ボタンでファイルを保存できます。
アドビアクロバットのOCR機能を使用する
光学式文字認識(OCR)は、画像内の文字を認識し、編集可能なテキストに変換する技術です。
今回の記事では、Adobe Acrobat Pro DC の OCR 機能を使用してテキストを抽出する方法を説明します。
* Adobe Acrobat Reader DC の無料版では、テキストを抽出することはできませんのでご注意ください。
お使いのPCにアドビアクロバットスタンダード/プロDCをまだインストールしていない場合は、以下のリンクから購入できます。

スキャンした画像の PDF を Adobe Acrobat Pro DC で開きます。
画面右側のメニューから、[Edit PDF].
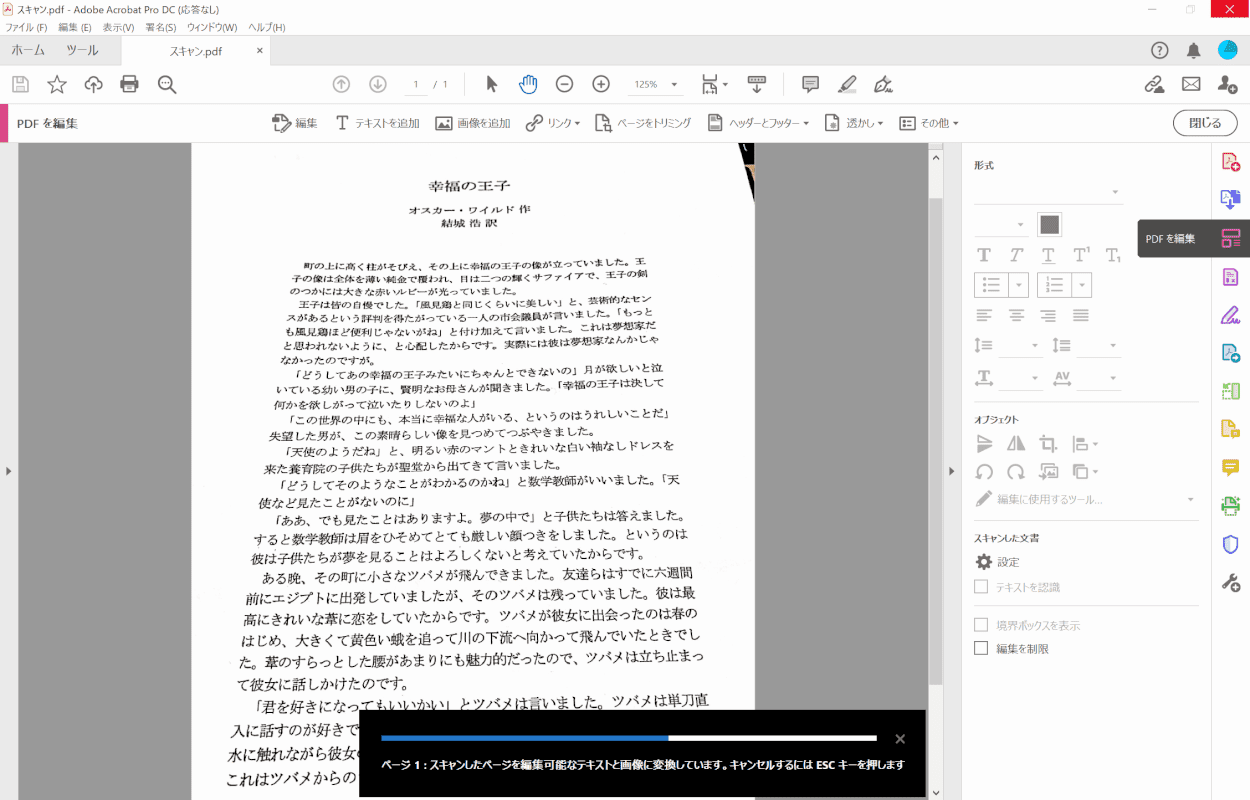
文字認識が開始されます。
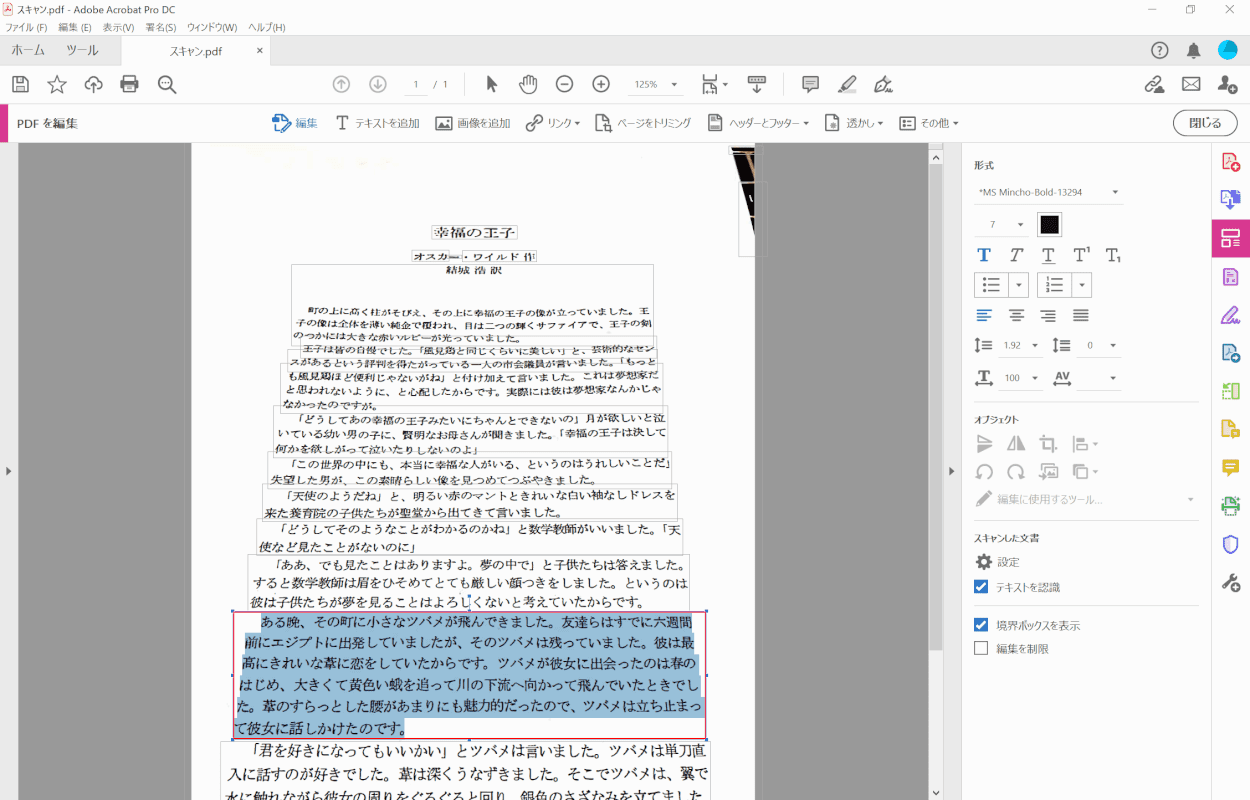
PDFは編集可能なテキストと画像に変換されました。
選ぶ[Text you want to extract].
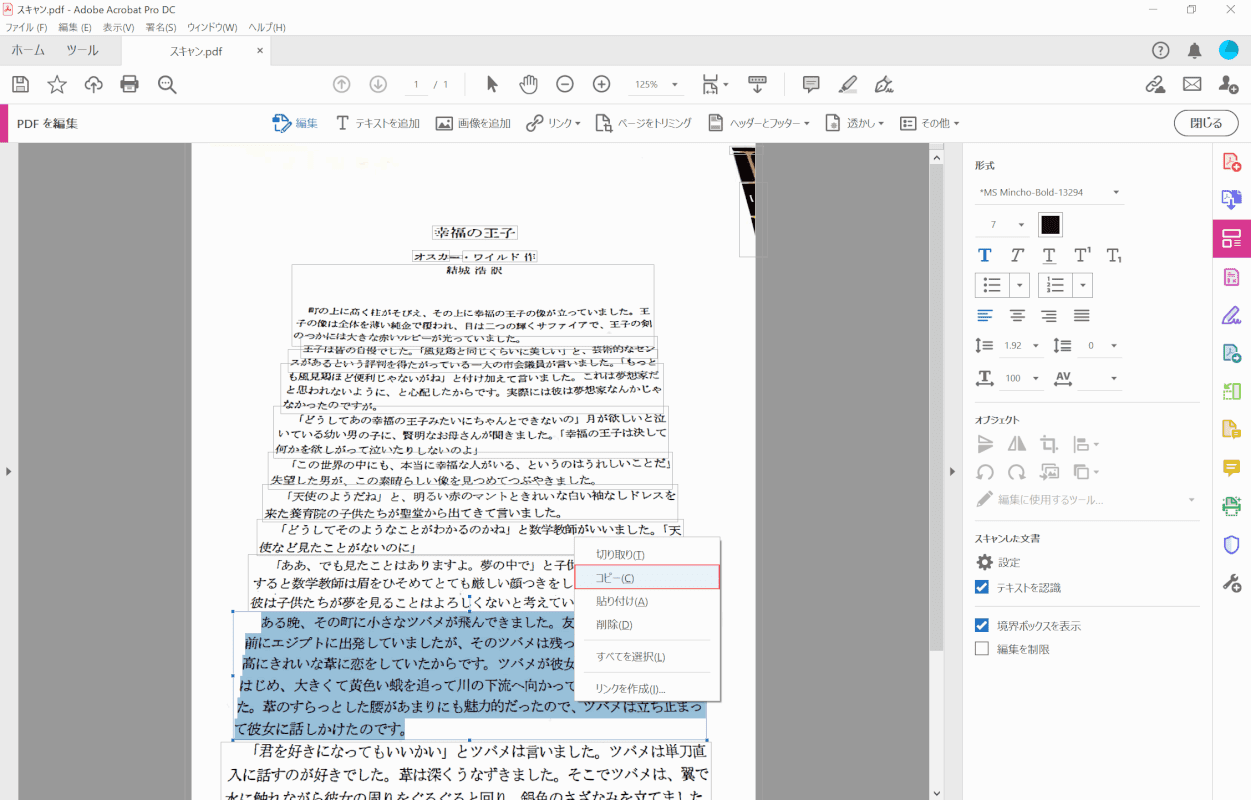
選択したテキストを「右クリック」して選択します。[Copy]出てきたメニューから。

始める[Document creation software (e.g. Notepad)].
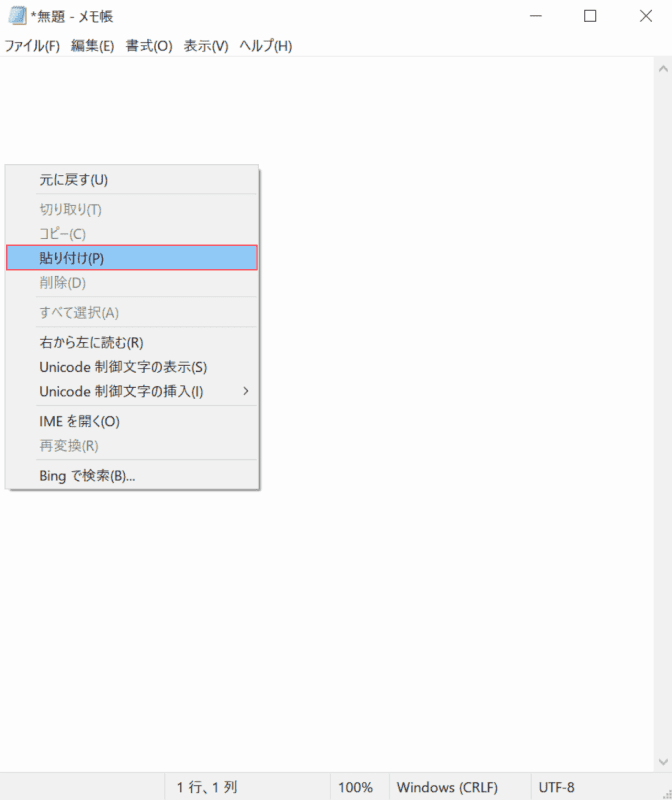
空白を「右クリック」して選択します。[Paste]出てきたメニューから。

これでテキストの抽出が完了しました。
PDF にテキストを送信できない場合
Adobe Acrobat Pro DC を使用してテキストを抽出しても機能しない場合は、次の方法でスキャンした画像を修正してみてください。

スキャンした画像の PDF を Adobe Acrobat Pro DC で開きます。
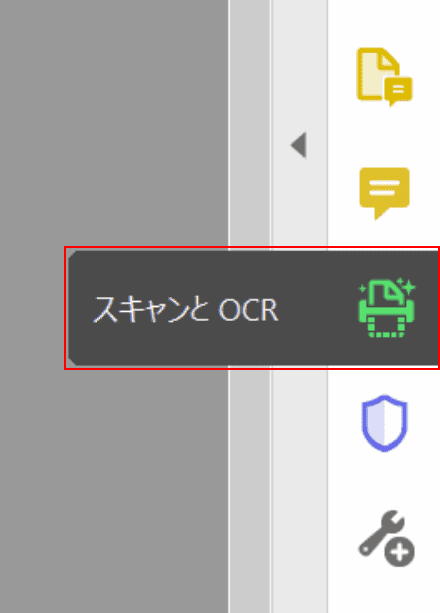
選ぶ[Scan and OCR]画面右側のメニューから。
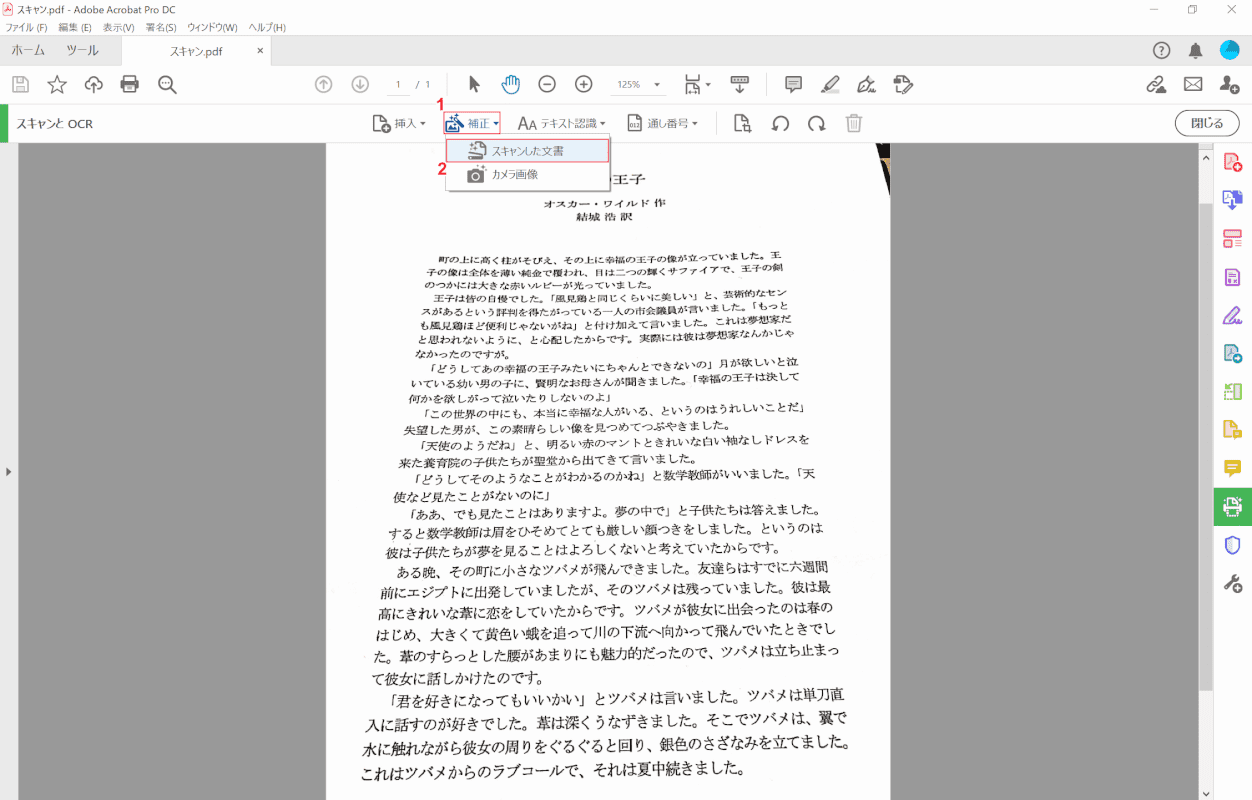
選択 (1)[Correction]および (2)[Scanned Documents].
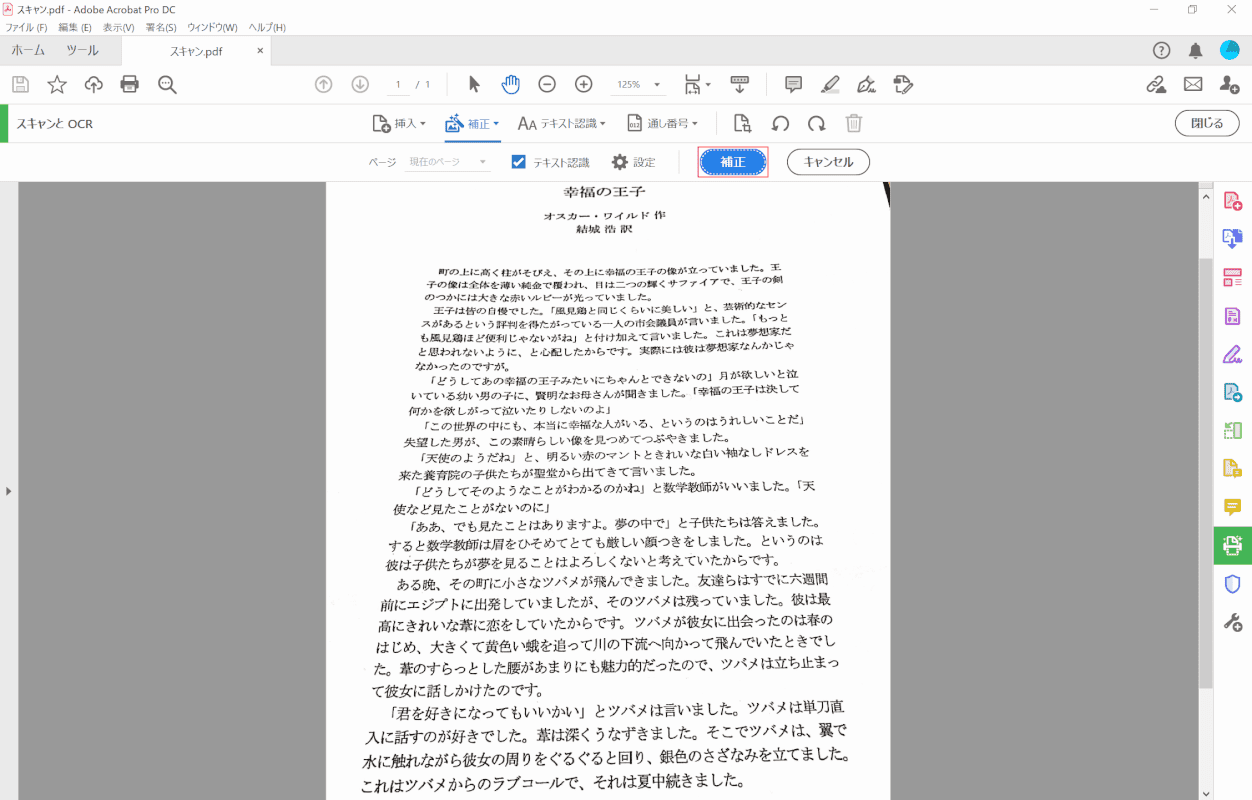
[[Correction]ボタン。
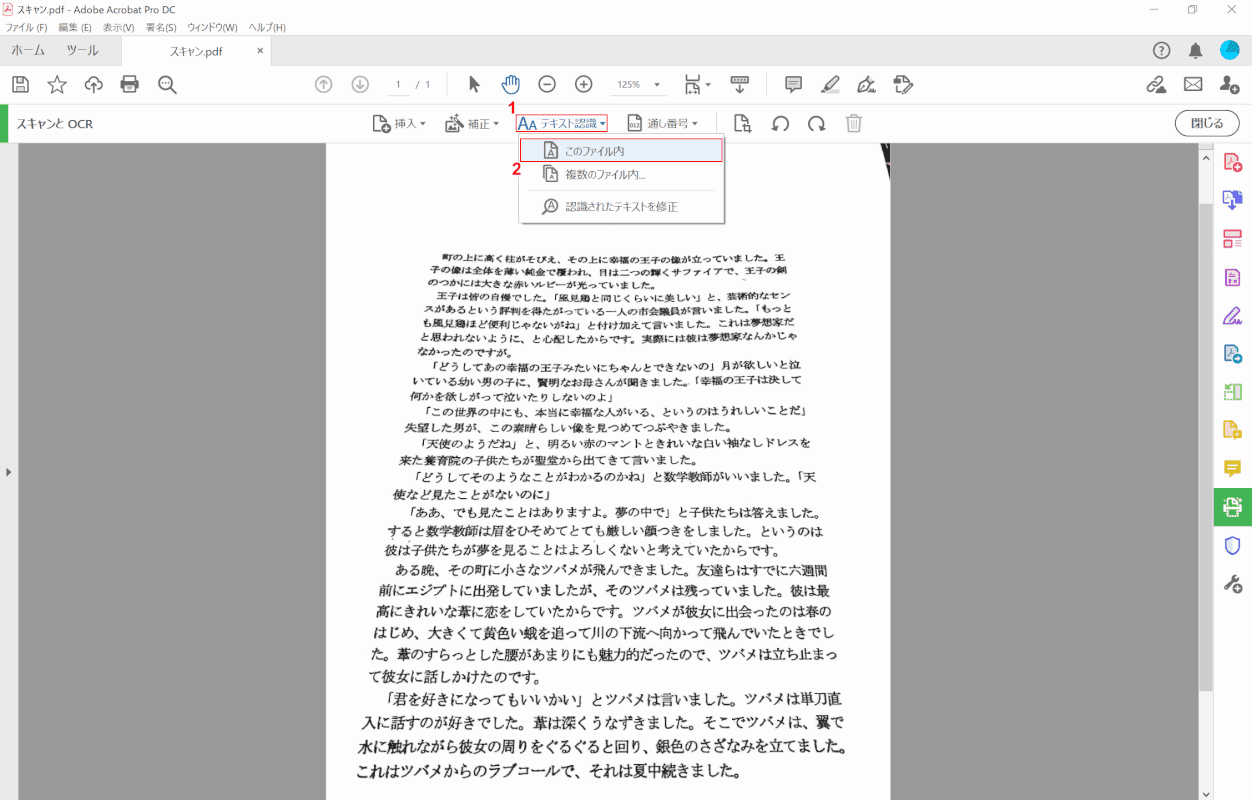
(1) 選択[Recognition of text](2)[In this file].
[[Text Recognition]ボタン。

これで、テキストが抽出可能になりました。